# Reinforcement Learning with Human Feedback Notes
So far in this course, we have discussed reinforcement learning (RL) in the context of games like Pac-Man or simulators like Cart-Pole. In these settings, the reward that our agent gets at each time step can be extracted from the environment. For example, we could define the Pac-Man reward as the number of pellets eaten or the Cart-Pole reward as the time that the pole stays up. However, in many real-life settings, **extracting useful reward from the environment alone is simply not possible!** Consider the case of text generation through large language models (LLMs). How do we assign a value to the "usefulness" or "creativity" of text? For humans, answering this query for a single response is quite easy, but it is difficult to imagine how we might quantify our preferences to create a reward function usable for reinforcement learning.
In this lecture, we discuss how to adapt RL methodology we have already learned about to work in domains where defining an objective reward function relies on human preferences and feedback. In particular, we explore LLM text generation example in more depth.
## LLMs as a Markov Decision Process
In order to design RL methods to encode human preferences in LLMs, we must first reimagine the text generation task as a Markov Decision Process (MDP). Recall that an MDP consists of five main components: the state space $ \mathcal{S} $, the action space $ \mathcal{A} $, the transition model $ \mathcal{P} $, the reward function $ \mathcal{R} $, and the discount factor $ \gamma $. Given this MDP, we want to define a policy $ \pi $ that chooses actions based on the current state.
Let's consider what each of these MDP components should be in the text generation setting:
**State**: Let $ \mathcal{S} $ denote the state space, and define a state $ s $ as the sequence of tokens (generated or provided) thus far. For example, suppose our LLM generated the following partial sentence:
> *Professor Kilian Weinberger is my favorite...*
Then, we can define the current state $ s $ as "*Professor Kilian Weinberger is my favorite*".
**Action**: Let $ \mathcal{A} $ denote the action space. Given this definition of state, an action $ a $ would be the next generated token. For instance, if the LLM decided to take generate "*comedian*" as the next token, then our action $ a $ is "*comedian*".
**Transition**: Let $ \mathcal{P} $ denote the transition model. When we formulate states and actions as above, it is clear that the transition to the next state given the current state and action is deterministic. To get from one state to the next, we just add the new generated token to the end of the existing sequence to create the next state $ s' $.
**Reward**: Let $ \mathcal{R} $ denote the reward function. As discussed before, it is not immediately apparent how to model reward in this setting. However, remember that the ultimate goal is to generate text that humans like and find useful. Therefore, let's wait until the entire sequence is generated and then assign it a score up to +1 if a human would prefer it and down to -1 otherwise. We'll discuss how to get these rewards in more detail later.
**Discount factor**: Let $ \gamma $ denote the discount factor. Since our reward only appears once at the very end of the sequence, it does not benefit us to have a discount factor of less than 1.0 as we have no need to balance current vs. future rewards. Therefore, let's set $ \gamma = 1 $.
**Policy**: Let $ \pi $ denote the policy. Given this MDP, we can let the policy $ \pi $ be an auto-regressive LLM of choice; it will decide which action to take (next token) given the current state (current sequence). For notational clarity, you might see us refer to this LLM policy as $ \pi_\theta $, where $ \theta $ represents the parameters of the LLM, and use $ \pi $ interchangeably.
## Computing Advantage
The Q-function and Value function are important in optimizing a policy on their own, but if we are in state $ s $, it is often useful to consider the benefit of pursuing a candidate action $ a $ over the action $ \pi(s) $ that the policy suggests. Therefore, we define the advantage function:
$$A^{\pi}(s_t, a_t) := Q^{\pi}(s_t, a_t) - V^{\pi}(s_t)$$
The advantage function tells us how much better selecting action $ a_t $ and then following policy $ \pi_t $ for the remainder of the trajectory is compared to just using $ \pi_t $ for our whole trajectory. Note that $ a_t $ could be the same action that policy suggests (in which case the advantage is 0) or it could be a completely different action!
One common application of the advantage function is to stabilize the training of the REINFORCE algorithm:
$$\theta \leftarrow \nabla_\theta \log \pi_\theta(a_t | s_t) (G_t) \implies \theta \leftarrow \nabla_\theta \log \pi_\theta(a_t | s_t) (G_t - b(s_t))$$
In this case, $ G_t $ is a sampled estimate of future rewards after taking action $ a_t $ (which is just the Q-function) and $ b(s_t) $ is the average future reward across all actions (which is precisely the value function), so we recognize this update as precisely the advantage function!
We can translate this idea to the text generation task. Imagine we would like to analyze the reward of predicting "good" after "It is". Here are three possible sentences:
> "It is good to work hard."
>
> "It is good to hurt people."
>
> "It is good to wear orange."
The first sentence is clearly good, the second sentence is clearly bad, and the third sentence is clearly neutral. However, if we examine each sentence on their own, it is difficult to understand how "good" and how "bad" the sentences truly are, particularly with the third sentence. However, if we compare the quality of one sentence compared to the quality of the average reponse for example, the relative performance of the model is much easier to understand.
Let's explore this idea further by introducing a new RL training method: Group Relative Policy Optimization.
## Group Relative Policy Optimization
If we would like to improve an LLM with human feedback, analyzing the feedback of a **single** individual on a **single** response is noisy. For example, since humans may want different types of outputs from an LLM, certain individuals may really like a response given by the model, but others may really dislike the same response. To stabilize reward signals offered by humans, it is helpful to use a **group** of responses rather than just a single response!
The Group Relative Policy Optimization (GRPO) algorithm does exactly this! To understand how it works, let's walk through an example of GRPO. Imagine we sampled a bunch of questions (prompts) that we want to ask the LLM. Let's say the first prompt is "Explain the moon landing to me as if I were 6 years old." First, we generate $ k $ responses per prompt, and we ask for human feedback for each response!
> *Prompt 1: The moon landing was when astronauts flew a big rocket to the moon, and one of them stepped out onto the moon's surface. It was the first time anyone had ever walked on the moon!*
> **Human: This is good! +5**
> *Prompt 2: The moon landing was when astronauts went to space in a rocket and then did some stuff on the moon. They walked around and there was a flag, and it was a big deal, I think.*
> **Human: This is bad! -10**
> *Prompt 3: In 1969, astronauts went to the moon in a spaceship. They landed on the moon, got out, and left some footprints and a flag. It was a super big adventure!*
> **Human: This is really good! +35**
Our first and third responses received positive feedback and our second response received negative feedback, and there is a reward associated with each response! Next, we just compute how much better each response did compared to the average score. This gives us the advantage of each response!
Group Baseline (Average Score): $ \frac{35 - 10 + 5}{3} = 10 $
Prompt 1 Advantage: 5 - 10 = -5
Prompt 2 Advantage: -10 - 10 = -20
Prompt 3 Advantage: 35 - 10 = 25
In this case, prompt 3 is much better than prompts 1 and 2, so it is the only prompt with positive advantage. Also notice that even though prompt 1 received a positive reward, its advantage was still negative because prompt 3 was so good. Consequently, the GRPO algorithm would increase the probability of generating prompt 3 (the only prompt with positive advantage) and decrease the probability of generating responses 1 and 2.
We can now formally present a simplfied version of the GRPO algorithm, which is a generalization of our example above:

[Source: Author]
Note that the term $ \nabla_\theta A(r_{ij}) $ is a simplified version of the real gradient of the objective function. We will briefly touch on what the objective function looks like in practice in the following section.
## GRPO in Action
DeepSeek AI shocked the world when it released a pair of advanced reasoning models that rivalled the performance of state-of-the-art models including OpenAI's o1 and Anthropic's Claude Sonnet 3.5 at a fraction of the cost. How did they do it? It turns out that GRPO was one of the keys to their success. We take a closer look at DeepSeek's R1-Zero and R1 models as an example of GRPO's real-world applicability.
### Case Study: DeepSeek R1-Zero
The goal of the DeepSeek R1-Zero model was to obtain advanced reasoning capabilities from a base model without any supervised fine-tuning (SFT) through pure reinforcement learning. The R1-Zero model training consists of two main stages: pre-training using imitation learning and tuning using GRPO.
#### Imitation learning:
The base policy network can be trained through imitation learning (also known as behavior cloning). First, collect a dataset of high quality expert demonstrations (like a human working through a math or programming problem). Second, treat each demonstration as independent and identically distributed (i.i.d) state-action pairs. For example, consider this simple "expert" demonstration:
> Human expert: *I want to solve 1 + 1 + 1. I know that 1 + 1 = 2. So 1 + 1 + 1 must equal 2 + 1. 2 + 1 = 3, so therefore 1 + 1 + 1 =3*
I could break this demonstration down into state-action pairs. Here is one such pair:
> State: "*I want to solve 1 + 1 + 1. I know that 1 + 1 =*", Action = "2"
Using these collected state-action pairs, we can do supervised training on our policy network to accurately predict the ground-truth action (i.e. next token prediction). This pre-training step allows the model to generate reasonable responses, but still lacks the ability to reason about more difficult questions. DeepSeek's pretrained model only achieved 15% on the AIME 2024, a challenging math competition benchmark. In order to improve the reasoning capabilities, we can use GRPO!
#### GRPO Finetuning
While we introduced GRPO using a human preference-based reward example, GRPO also works with other reward signals. While training R1-Zero, the DeepSeek team decided not include the human preference reward model in order to simplify the training pipeline. Instead, they opted to use an accuracy reward (e.g. correct math computation, successful code compilation, etc.) and a formatting reward (e.g. encouraging structured chain-of-thought generations). Using these reward signals, they ran GRPO to finetune the pre-trained model. DeepSeek R1-Zero uses a slightly more complex version of the objective function defined above:

[Source: Author]
The specifics of the clipped advantage (underline blue) is out of the scope of these notes, but the general premise is to make positive advantage sequences more likely and negative advantage sequences less likely without making $ \pi_\theta $ too different from the original policy $ \pi_{ref} $. The KL-divergence portion of the objective (underline orange) also punishes extreme deviations from the original policy to incentivize stable training dynamics.
After GRPO finetuning using the new objective function above, DeepSeek-R1-Zero achieved massive performance gains on the AIME 2024 benchmark - achieving an accuracy of 71% (compared to 15% before GRPO)! This result emphasized the immense potential for RL finetuning to elicit reasoning capabilities from pre-trained models without the need for expensive SFT.
### Incorporating Human Feedback: DeepSeek R1
Although the performance of DeepSeek-R1-Zero was impressive, the authors found that there were several issues with human readability and language mixing. This can be partially attributed to the lack of human preference data. The authors looked to interate on the ideas of R1-Zero to create DeepSeek-R1. In particular, the authors introduce SFT layers into the training regime (details beyond the scope of these notes). Additionally, in the final step, they run another round of GRPO to encode human preferences for readability by learning a reward model through human feedback. The following diagram provides an simplified overview of the DeepSeek-R1 training regime:
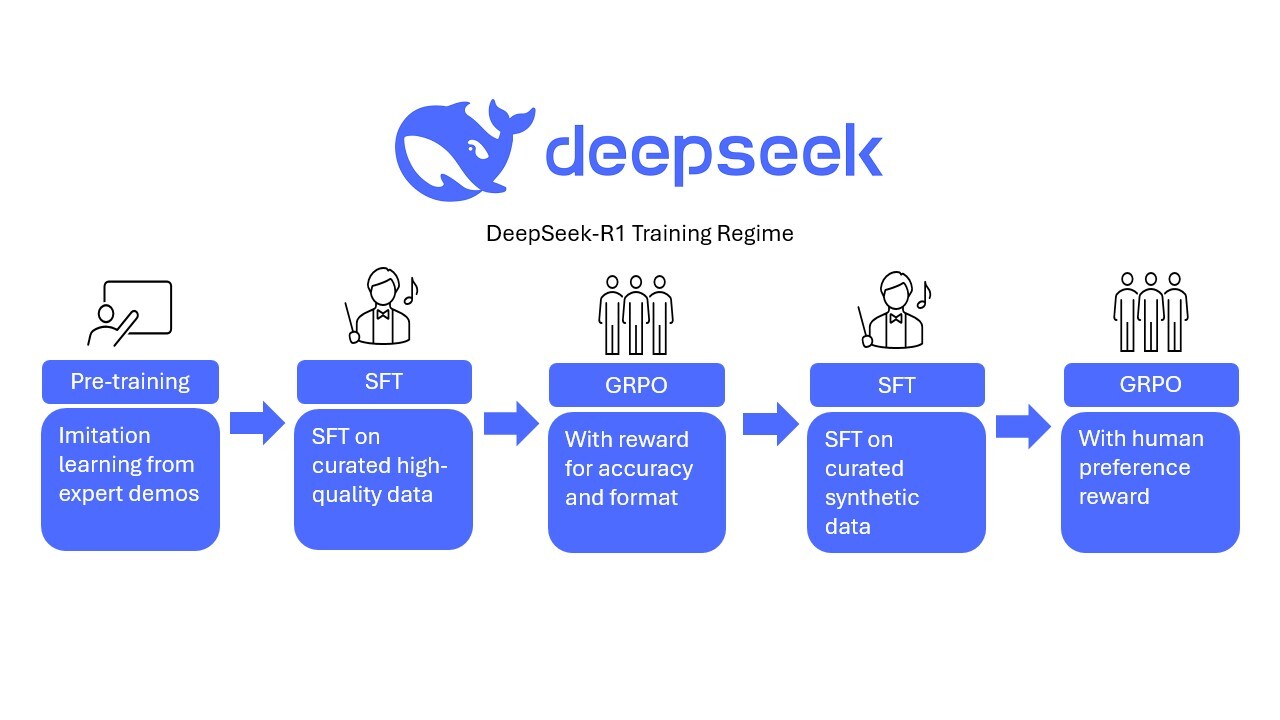
[Source: Author]
How do we quantify human preferences in the final step of the DeepSeek-R1 regime? We can learn reward models from human annotations.
## Quantifying Human Preferences
### Reward Model Training
In the previous section, we introduced the idea of using reward signals from human feedback to train our model, but what does that really mean? How do we quantify response creativity, honesty, politeness, or other qualities we would like our model to have? One such approach is to train a model of the reward function that models how a human would react to a given response! Let's take a look back at a previous example to understand how to create this reward model. Here are two sample responses generated by our model:
> Response 1: *"It is good to work hard."*
>
> Response 2: *"It is good to hurt people."*
Imagine we wanted to train our reward model to give non-harmful answers. To train the model, we ask a human to rank the responses based on the given criteria. For our example, a human might rank the responses as 1 > 2. Now, let's turn this preference into a reward signal.
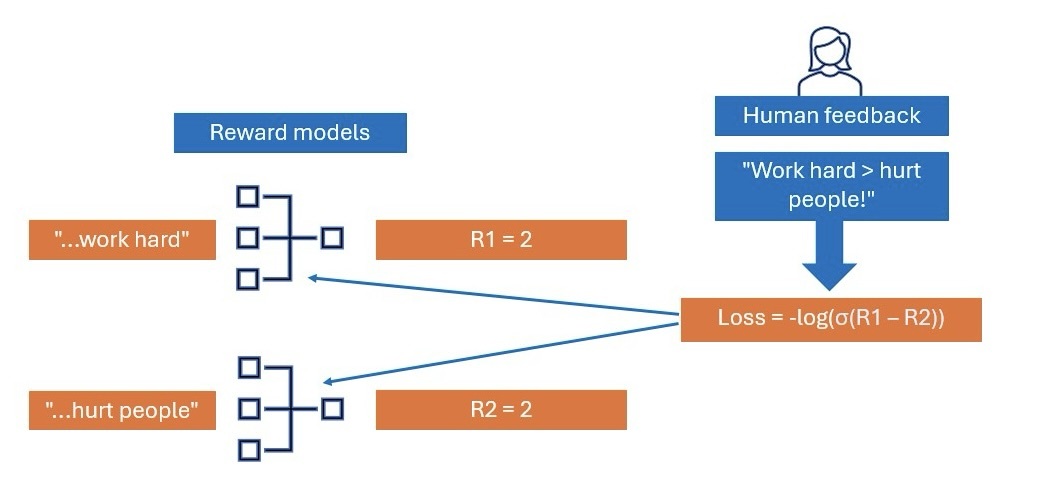
[Source: Author]
By using a negative log loss that is guided by the human feedback (i.e. human feedback dictates the order of the generated rewards in the loss function), we can train a reward model that assigns high reward to responses that align with human preferences and low reward to those that don't.
We can then use this reward model in GRPO or any RL method we would like to help guide generations towards human-preferred outputs.
### Limitations of RLHF
Ultimately, RLHF relies on accurate human labeling, which involves a high degree of variance. For example, some people may find a response to be factual or non-harmful, whereas others may find the *same* response harmful and inaccurate. This can make the reward model learned from labelers very noisy which can make training unstable and difficult to control and introduces a dependence between the performance of the model and the accuracy of the labelers. However, as showcased by DeepSeek, RLHF has huge potential to improve LLMs substantially, and it will be cool to see how recent innovations in RLHF will transform AI capabilities!